| No | 기본지식 내용 | 유투브 |
| 1 | 배치 정규화(Batch Normalization) | 강좌 |
| 2 | LSTM 쉽게 이해하기 | 강좌 |
| 3 | Sequence Data를 위한 RNN & LSTM | 강좌 |
Paper Review
DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement
Author : Yanxin Hu , Yun Liu2, Shubo Lv1, Mengtao Xing, Shimin Zhang, Yihui Fu, Jian Wu, Bihong Zhang, Lei Xie
Date : 23 Sep 2020
[ Abstraction ]
Speech Enhancement는 명료성 및 품질 측면에서 딥러닝의 성공으로 인해 혜택을 받았다. 기존의 시간-주파수(TF) 도메인에서의 Processing 방법은 단순한 컨볼루션 신경망 네트워크(CNN) 또는 반복 신경망 네트워크(RNN)를 통해 TF 마스크 또는 음성 스펙트럼을 예측하는데 초점을 맞추었다. 최근의 일부 연구에서는 Complex-valued 스펙트로그램을 학습(훈련) 타겟으로 사용하지만, Real-valued 네트워크에서 학습(훈련)하여 Magnitude와 Phase 구성 요소 또는 실수 및 허수 부분을 각각 예측한다. 특히, CRN (Convolution Recurrent Network)은 Complex 타겟에 유용한 것으로 입증된 CED (Convolutional Encoder-Decoder) 구조와 LSTM을 통합한다. Complex 타겟을 보다 효과적으로 학습(훈련)시키기 위해, 본 논문에서는 DCCRN (Deep Complex Convolution Recurrent Network)이라고하는 Complex-valued 연산을 시뮬레이션하는 새로운 네트워크 구조를 설계한다. 여기서 CNN 및 RNN 구조는 모두 Complex-valued 연산을 처리 할 수 있다. 제안된 DCCRN 모델은 객관적 또는 주관적 메트릭에서 이전의 다른 네트워크에 비해 매우 경쟁력이 있다. DCCRN 모델은 3.7M 파라미터로 Interspeech 2020 DNS (Deep Noise Suppression) 챌린지에 제출되었으며 실시간 트랙에서는 평균 의견 점수(MOS) 기준으로 1위, 비실시간 트랙에서는 2위를 차지했다.
Index Terms: Speech Enhancement, Denoise, Deep Learning, Complex Network
1. Introduction
잡음 간섭은 음성 통신의 지각 품질과 파악 능력을 심각하게 저하시킬 수 있다. 마찬가지로 자동 음성 인식(ASR)과 같은 관련 작업도 잡음 간섭의 영향을 많이 받을 수 있다. 따라서 Speech Enhancement는 잡음이있는 음성을 입력으로 받아들이고, 더 나은 음성 품질, 명료도 및 때로는 다운 스트림 작업에서 더 나은 기준(예 : ASR의 낮은 오류율)을 위해 향상된 음성 출력을 생성하는 매우 바람직한 작업이다. 최근 딥러닝(DL) 방법은 Speech Enhancement, 특히 어려운 조건에서 비정상 잡음을 처리하는데 있어 유망한 결과를 얻고 있다. DL는 특정 애플리케이션에 따라 단일 채널(모노) 및 다중 채널 Speech Enhancement에 모두 도움이 될 수 있다. 이 논문에서는 특히 모델 복잡도가 낮은 실시간 프로세싱을 목표로하는 인식 품질 및 인텔리전스 향상을 위한 DL 기반 단일 채널 Speech Enhancement에 중점을 두고 있다. Interspeech 2020 DNS 챌린지는 이러한 목적을위한 공통 테스트 베드를 제공했다[1].
1.1 Related Work
슈퍼바이즈드 학습(훈련) 문제로 공식화된, 잡음 섞인 음성은 시간-주파수(TF) 도메인에서 혹은 직접적인 시간 도메인에서 신경망에 의해 향상 될 수 있다. 시간 도메인 접근방식은 직접 회귀[2,3]와 적응형 프런트-엔드 접근방식[4–6]의 두 가지 범주로 나눌 수 있다. 전자는 일반적으로 어떤 형태의 1-D 컨볼 루션 신경망(Conv1d)을 포함하여 명시적인 신호 프런트-엔드 없이 음성-잡음 혼합 파형에서 대상 음성으로 회귀 함수를 직접 학습한다. 시간 도메인 신호를 입력 및 출력하는 후자의 적응형 프런트 엔드 접근 방식은 일반적으로 단시간 푸리에 변환(STFT) 및 역변환(iSTFT)과 유사한 컨볼루션 인코더-디코더(CED) 또는 U-Net 프레임 워크를 채택한다. 그런 다음, 인코더와 디코더 사이에 향상 네트워크가 삽입됩되며, 일반적으로 시간적 컨볼루션 네트워크 (TCN)[4, 7] 및 LSTM (long short term memory) [8]과 같은 시간 모델링 기능을 가진 네트워크를 사용한다.
또 다른 주류로서, TF 도메인 접근법[9–13]은 STFT 이후에 TF 표현을 사용하여, 미세한 음성 및 잡음 구조를 더 분리 할 수 있다는 믿음으로 스펙트로그램에 대한 작업을 수행한다. Convolution Recurrent Network (CRN) [14]는 시간 도메인 접근방식과 유사한 CED 구조를 사용하지만, 잡음이 있는 음성 스펙트로그램에서 2-D CNN (Conv2d)을 통해 더 나은 분리를 위한 높은 수준의 특징을 추출하는 최근의 접근 방식이다. 특히 CED는 Complex-valued 또는 Real-valued 스펙트로그램을 입력으로 사용할 수 있다. Complex-valued 스펙트로그램은 극좌표의 Magnitude와 Phase으로 분해되거나, 데카르트 좌표의 실수 및 허수 부분으로 분해 될 수 있다. 오랫동안, Phase는 추정하기 어렵다고 믿어졌다. 따라서 초기 연구는 Phase[15–17]를 무시한 채 Magnitude 관련 학습(훈련) 목표에만 초점을 맞추고, 단순히 잡음섞인 음성 Phase에 추정된 Magniture를 적용하여 추정된 음성을 다시 합성한다. 따라서 이는 성능의 상한을 제한하는 반면, 추정된 음성의 Phase는 심각한 간섭으로 인해 크게 달라질 것이다. 이 문제를 해결하기 위해, Phase 재구성에 대한 많은 최근 접근방식이 제안되었지만 [18, 19], 신경망은 실제 가치를 유지한다.
일반적으로 TF 도메인에서 정의된 학습(훈련) 대상은 주로 두 개의 그룹, 즉 깨끗한 음성과 배경 잡음 사이의 시간 주파수 관계를 설명하는 마스킹 기반 대상과 깨끗한 음성의 스펙트럼 표현에 해당하는 매핑 기반 대상으로 분류된다. 마스킹 제품군에서 이상적인 이진 마스크(IBM)[20], 이상적인 비율 마스크(IRM)[10] 및 스펙트럼 Magnitude 마스크(SMM)[21]는 Phase 정보는 무시하고 깨끗한 음성과 혼합 음성 사이의 Magnitude만 사용한다. 대조적으로, Phase 감지 마스크 (PSM) [22]는 Phase 추정의 실현 가능성을 보여주는 Phase 정보를 활용한 최초의 마스크였다. 그 후, Complext 비율 마스크 (CRM) [23]가 제안되었는데, 이는 깨끗한 음성과 혼합 음성 스펙트로그램의 분할의 실제 및 가상 구성 요소를 동시에 향상시켜 음성을 완벽하게 재구성 할 수 있었다. 이후, Tan et al. [24] 연구진은 혼합 음성의 실제 및 가상의 스펙트로그램을 동시에 추정하기 위해 Complex 스펙트럼 매핑 (CSM)을 위해 하나의 인코더와 두 개의 디코더를 가진 CRN을 제안했다. CRM 및 CSM은 이론상 최고의 오라클 음성 향상 성능을 달성 할 수 있도록 음성 신호의 모든 정보를 보유하고 있다는 점을 주목할 필요가 있다.
상기의 접근방식은 Phase 정보가 고려되었지만 Real valued 네트워크에서 학습되었다. 최근, Deep Complex U-Net[25]은 Complex valued 스펙트로그램을 다루기 위해 Deep Complext 네트워크[26]와 U-net[27]의 장점을 결합했다. 특히, DCUNET은 CRM을 추정하도록 훈련되었으며, 출력 TF-도메인 스펙트로그램을 iSTFT에 의해 시간 영역 파형으로 변환한 후, SI-SNR(Scale-invariant Source-to-Noise Ratio) 손실[4]을 최적화한다. 시간 모델링 기능으로 최첨단 성능을 달성하면서도 중요한 컨텍스트 정보를 추출하기 위해 많은 층의 컨볼루션(convolution)이 채택되어 모델 크기와 복잡성이 커지므로 효율성에 민감한 애플리케이션에서 실제 사용이 제한된다.
1.2 Contributions
본 논문에서, 우리는 이전의 네트워크 아키텍처를 기반으로 DCCRN (Deep Complex Convolution Recurrent Network)라고 불리는 새로운 Complex Valued Speech Enhancement 네트워크를 설계하여 SI-SNR 손실을 최적화한다. 네트워크는 DCUNET과 CRN의 장점을 효과적으로 결합하며, LSTM을 사용하여 학습(훈련) 가능한 파라미터와 계산 비용을 크게 줄인 시간적 컨텍스트를 모델링한다. 제안된 DCCRN 프레임워크 하에서, 우리는 또한 다양한 학습(훈련) 목표를 비교하고, Complex 네트워크와 Complex 타겟을 통해 최고의 성과를 얻을 수 있다. 우리의 실험에서는, 제안된 DCCRN이 CRN[24]을 큰 차이로 능가한다는 것을 발견했다. 계산 복잡성이 1/6에 불과한 DCCRN은 유사한 모델 파라미터 구성에서 DCUNET [25]을 통해 경쟁력있는 성능을 달성한다. 우리의 모델은 단 3.7M 파라미터로 실시간 음성 향상을 목표로 하고 있지만 DNS 과제에서 P.808 주관적 평가에 따르면 실시간 트랙에서 최고의 MOS와 비실시간 트랙에서 두 번째로 우수한 MOS를 달성했다.
2. The DCCRN Model
2.1 Convolution recurrent network architecture
Convolution Recurrent Network (CRN, 원래 [14]에서 설명됨)는 기본적으로 인코더와 디코더 사이에 두 개의 LSTM 레이어가 있는 본질적인 CED 아키텍처이다. 여기서 LSTM은 특히 시간적 의존성을 모델링하는데 사용된다. 인코더는 입력 특성에서 높은 수준의 특성을 추출하거나 해상도를 줄이는 것을 목표로하는 5개의 Conv2d 블록으로 구성된다. 이후, 디코더는 저해상도 특성의 입력을 원래 크기로 재구성하는 인코더-디코더 구조의 대칭 설계로 전환된다. 구체적으로는 인코더/디코더 Conv2d 블록은 컨볼루션/디컨볼루션 계층과 배치 정규화 및 활성화 함수로 구성된다. 스킵 연결은 인코더와 디코더를 집중시켜 그래디언트 흐름에 도움이된다.
Magnitude 맵핑이 적용된 원래 CRN과 달리, Tan et al. [24] 연구진은 최근 입력 혼합에서 깨끗한 음성으로 Complex STFT 스펙트로그램의 실수 부분과 허수 부분을 모델링하기 위해 하나의 인코더와 두 개의 디코더를 가진 수정된 구조를 제안하였다. 기존의 Magnitude만 목표한 것에 비해 Magnitude와 Phase를 동시에 향상시킴으로써 괄목할 만한 개선 효과를 얻었다. 그러나, 그들은 실수부분과 허수부분을 두 개의 입력 채널로 다루며, Complex 곱셈 규칙에 제한되지 않는 하나의 공유된 Real valued 컨볼루션 필터로 Real valued 컨볼루션 연산만 적용한다. 따라서 네트워크는 사전 지식없이 실제 및 가상 부분을 학습 할 수 있다. 이 문제를 해결하기 위해서, 이 논문에서 제안된 DCCRN은 인코더/디코더에서 Complex CNN 및 Complex 배치 정규화 레이어로 CRN을 실질적으로 수정하고 Complex LSTM도 기존 LSTM을 대체한다. 특히 Complex 모듈은 Complex 곱셈의 시뮬레이션을 통해 Magnitude와 Phase 간의 상관 관계를 모델링한다.
| 그림 1 : DCCRN network |
 |
2.2 Encoder and decoder with complex network
Complex 인코더 블록에는 Complex Conv2d, Complex 배치 정규화 [26] 및 Real valued PReLU [28]가 포함된다.
Complex 배치 정규화 및 PReLU는 원래 논문의 구현을 따른다. 우리는 DCUNET의 Complex Conv2d 블록[25]에 따라 Complex Conv2d 블록을 설계한다. Complex Conv2d는 인코더 전체의 Complex 정보 흐름을 제어하는 4개의 기존 Conv2d 작업으로 구성된다. Complex 컨볼루션 필터 W는 W = Wr + jWi로 정의되며, 여기서 실수 행렬 Wr 및 Wi는 각각 Complex 컨볼루션 커널의 실수부와 허수부를 나타낸다. 동시에 입력 Complex 행렬 X = Xr + jXi를 정의한다. 따라서 Complex 컨볼루션 연산 X*W에서 복잡한 출력 Y를 얻을 수 있다 :
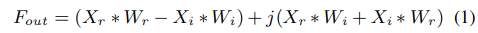
여기서 Fout은 하나의 Complex 레이어의 출력 기능을 나타낸다.
Complex 컨볼루션과 유사하게 Complex 입력 Xr 및 Xi의 실수 부분과 허수 부분이 주어지면 Complex LSTM 출력 Fout은 다음과 같이 정의 할 수 있다 :

여기서 LSTMr 및 LSTMi는 실수 부분과 허수 부분의 두 가지 전통적인 LSTM을 나타내고 Fri는 LSTMi를 사용하여 입력 Xr에 의해 계산된다.
| 그림 2 : Complex module |
 |
2.3 Training target
학습(훈련)시, DCCRN은 CRM을 추정하고 신호 근사(SA)에 의해 최적화된다. 깨끗한 음성 S 및 잡음이 있는 음성 Y의 Complex valued STFT 스펙트로그램이 주어지면 CRM은 다음과 같이 정의할 수 있다 :

여기서 Yr과 Yi는 각각 잡음이 있는 Complex valued 스펙트로그램의 실수 부분과 허수 부분을 나타낸다. 깨끗한 Complex 스펙트로그램의 실수 부분 및 허수 부분은 Sr 및 Si로 표시됩니다. Magnitude 목표 SMM도 비교에 사용할 수 있다 :

여기서 |S| 및 |Y| 각각 깨끗한 음성과 잡음이 섞인 음성의 Magnitude를 나타낸다. 깨끗한 음성의 Magnitude 또는 Complex 스펙트로그램과 마스크가 적용된 잡음이 섞인 음성의 차이를 직접 최소화하는 신호 근사를 적용한다. SA의 손실 함수는 CSA = Loss (^M · Y, S) 및 MSA = Loss (|^M| · |Y|, |S|)가 된다. 여기서 CSA 및 MSA는 CRM 기반 SA 및 SMM 기반 SA를 나타낸다. 각각 또는 데카르트 좌표 표현 ^M = ^Mr + j^Mi는 극좌표로도 표현 될 수 있다 :

우리는 DCCRN에 대해 세 가지 곱셈 패턴을 사용할 수 있으며, 이는 곧 실험과 비교될 것이다. 구체적으로 추정 된 깨끗한 음성 ^S는 다음과 같이 계산 될 수있다 :

DCCRN-C는 CSA 방식으로 ^S를 획득하고 DCCRN-R은 각각 ^Y의 실수 부분과 허수 부분의 마스크를 추정한다. 또한 DCCRN-E는 극좌표로 수행하며 DCCRN-C와 수학적으로 유사하다. 차이점은 DCCRN-E는 tanh 활성화 함수를 사용하여 마스크 크기를 0에서 1로 제한한다는 것이다.
2.4. Loss function
모델 학습(훈련)의 손실함수는 SI-SNR로, 평균 제곱 오차(MSE)를 대체하기 위한 평가지표로 일반적으로 사용되었다. SI-SNR (Scale-invariant Source-to-Noise Ratio)은 다음과 같이 정의된다.

여기서 s 및 ^s는 각각 깨끗한 및 추정된 시간 도메인 파형이다. <·, ·>는 두 벡터 사이의 내적을 나타낸다. || · || 2는 유클리드 놈(L2 놈)이다. 세부적으로 STFT 커널 초기화 convolution / deconvolution 모듈을 사용하여 네트워크로 전송하고 손실함수를 계산하기 전에 파형을 분석 / 합성한다 [29].
3. Experiments
3.1 Datasets
우리는 실험에서, 먼저 제안된 모델과 WSJ0[30]에서 시뮬레이션된 데이터 세트의 여러 기준선을 평가한 후, 가장 잘 수행된 모델은 Interspeech20 DNS Challenge 데이터 세트[1]에서 추가로 평가되었다. 첫 번째 데이터 세트의 경우, 131명의 연설자(화자)(남성 66명, 여성 65명)를 포함하는 WSJ0[30]에서 24500개의 발화(약 50시간)를 선택한다. 학습(훈련), 검증 및 평가 세트를 각각 20000, 3000 및 1500 발화로 섞고 분할한다. 잡음 데이터 세트에는 6.2시간 자유 소음과 MUSAN의 42.6시간 음악[31]이 포함되어 있으며, 학습(훈련) 및 검증에 41.8시간을 사용하고 평가에 나머지 7시간을 사용한다. 학습(훈련)과 검증에서 음성-소음 혼합은 음성 세트와 소음 세트로부터 발화를 무작위로 선택하고 -5dB와 20dB 사이의 무작위 SNR에서 혼합함으로써 생성된다. 평가 세트는 5 개의 일반적인 SNR (0dB, 5dB, 10dB, 15dB, 20dB)에서 생성된다.
두 번째 빅 데이터 세트는 DNS 챌린지에서 제공한 데이터를 기반으로 한다. 180시간 DNS 챌린지 노이즈 세트에는 150개의 클래스와 65,000개의 노이즈 클립이 있으며, 깨끗한 음성 세트에는 2,150명의 연설자(화자)에서 500시간 이상의 클립이 포함되어 있다. 데이터 세트를 최대한 활용하기 위해 모델 학습(훈련) 중에 동적 혼합을 사용하여 음성-잡음 혼합을 시뮬레이션 한다. 구체적으로, 각 학습(훈련) Epoch에서 우리는 먼저 영상 방법 [32]에 의해 설정된 시뮬레이션 된 3000-RIR에서 무작위로 선택된 RIR (Room Impulse Response)로 음성과 잡음을 컨볼루션 한 다음 음성-잡음 혼합을 동적으로 생성한다. -5~20dB 사이의 임의 SNR에서 반향이 있는 음성과 잡음을 혼합한다. 모델이 '확인한' 총 데이터는 10 Epoch 학습(훈련)이 지난 후5000 시간이 넘는다. 우리는 객관적인 채점 및 최종 모델 선택을 위해 공식 테스트 세트를 사용한다.
3.2 Training setup and baselines
모든 모델에서 윈도우 길이와 홉 크기는 25ms 및 6.25ms이고 FFT 길이는 512이다. 우리는 Pytorch를 사용하여 모델을 학습(훈련)하고 최적화 프로그램은 Adam을 사용한다. 초기 학습률은 0.001로 설정되어 있으며 검증 손실이 증가하면 0.5가 감소한다. 모든 파형은 16kHz로 리샘플링 된다. 모델은 조기 중지로 선택 된다. DNS 챌린지에 대한 모델을 선택하기 위해 다음과 같이 WSJ0 시뮬레이션 데이터 세트에서 여러 모델을 비교한다.
| Model | 내 용 |
| LSTM | Semi-causal 모델에는 두 개의 LSTM 계층이 포함되어 있으며, 각 계층에는 800개의 유닛이 있다. 시간 차원에서 커널 크기가 7이고 미리보기가 6프레임인 Conv1d 레이어를 추가하여 Semi-causal을 달성한다. 출력 계층은 257개 단위의 완전 연결 계층이다. 입력과 출력은 각각 MSA를 사용하여 잡음이 있고 추정된 깨끗한 스펙트로그램이다. |
| CRN | Semi-causal 모델에는 [24]에서 최상의 구성을 가진 인코더 1개와 디코더 2개가 포함된다. 입력 및 출력은 잡음 및 추정된 STFT Complex 스펙트로그램의 실수 및 허수 부분이다. 2개의 디코더가 실수 부분과 허수 부분을 별도로 처리한다. 커널 크기는 주파수 및 시간 차원에서도 (3,2)이며 보폭은 (2,1)로 설정된다. 인코더의 경우 채널 차원에서 실수 부분과 허수 부분을 연결하므로 입력 특성의 모양은 [BatchSize, 2, Frequency, Time]이다. 또한 인코더의 각 레이어의 출력 채널은 {16,32,64,128,256,256} 이다. 숨겨진 LSTM 유닛은 256이고 1280 유닛이 있는 조밀한 레이어는 마지막 LSTM 이후이다. 스킵 연결로 인해 실수부분 또는 허수부분 디코더의 입력 채널의 각 레이어는 {512, 512, 256, 128, 64, 32} 이다. |
| DCCRN | 4 가지 모델은 DCCRN-R, DCCRN-C, DCCRN-E 및 DCCRN-CL (DCCRN-E와 같은 마스킹)로 구성된다. 이러한 모든 모델의 직류 구성 요소가 제거된다. 처음 세 DCCRN의 채널수는 {32, 64, 128, 128, 256, 256}이고 DCCRN-CL은 {32, 64, 128, 256, 256, 256}이다. 커널 크기와 보폭은 각각 (5,2) 및 (2,1)로 설정된다. 처음 3개의 DCCRN의 실제 LSTM은 256개의 유닛이 있는 2개의 레이어이고 DCCRN-CL은 실수 부분과 허수 부분에 대해 각각 128개의 유닛이 있는 Complex LSTM을 사용한다. 그리고 1024개 유닛으로 구성된 조밀한 레이어는 마지막 LSTM 이후이다. |
| DCUNET | 비교를 위해 DCUNET-16을 사용하고 시간 차원의 보폭은 DNS 챌린지 규칙에 맞게 1로 설정된다. 또한 인코더의 채널은 [72, 72, 144, 144, 144, 160, 160, 180]으로 설정된다. |
Semi-Casual Convolution [33]의 구현을 위해 실제로 일반적으로 사용되는 Casual Convolution과는 두 가지 차이점이 있다. 첫째, 인코더의 각 Conv2d에서 시간 차원 앞에 0을 채운다. 둘째, 디코더의 경우 각 컨볼루션 레이어에서 한 프레임을 미리 살펴 본다. 이로 인해 DNS 챌린지 제한 (40ms)으로 제한되는 6프레임 룩헤드 (전체 6 × 6.25 = 37.5ms)가 발생한다.
3.3 Experimental results and discussion
모델 성능은 시뮬레이션 된 WSJ0 데이터 세트에서 PESQ에 의해 먼저 평가된다. <표 1>은 테스트 세트의 PESQ 점수를 보여준다. 각각의 경우 최상의 결과는 굵은 숫자로 강조 표시된다.
| 표 1 : PESQ on the simulated WSJ0 dataset |
 |
시뮬레이션된 WSJ0 테스트 세트에서 4개의 DCCRN이 Complex 컨볼루션의 효과를 나타내는 기준선인 LSTM 및 CRN을 능가하는 것을 볼 수 있다. DCCRNCL은 다른 DCCRN보다 더 나은 성능을 제공한다. 이것은 또한 복잡한 LSTM이 Complex 목표 학습(훈련)에도 유익하다는 것을 보여준다. 더욱이, 우리는 완전 Complex valued 네트워크 DCCRN과 DCUNET이 PESQ에서 유사함을 알 수 있다. 런타임 테스트에 따르면 DCUNET의 계산 복잡도는 DCCRN-CL의 계산 복잡도의 거의 6배에 달합니다.
| 표 2 : PESQ on DNS challenge test set (simulated data only). T1 and T2 denote track 1 (real-time-track) and track 2 (nonreal-time-track). |
 |
| 표 3 : MOS on DNS challenge blind test set [1] |
 |
DNS 챌린지에서 우리는 DNS 데이터 세트를 사용하여 최고의 성능을 자랑하는 2개의 모델, DCCRN 모델과 DCUNET을 평가한다. <표 2>는 테스트 세트에 대한 PESQ 점수를 보여준다. 마찬가지로 DCCRN-CL은 일반적으로 DCCRN-E보다 약간 더 나은 PESQ를 달성한다. 그러나 내부 주제 청취 후 DCCRN-CL이 일부 클립의 음성 신호를 과도하게 억제하여 불쾌한 청취 경험을 초래할 수 있다는 것을 알게 되었다. DCUNET은 합성 비반사 세트에서 비교적 양호한 PESQ를 얻지만, 합성 반사 집합에서는 PESQ가 상당히 떨어진다. 우리는 객관적인 점수가 다른 시스템에 가까울 때 주관적인 청취가 매우 중요하다고 믿는다. 이러한 이유로, DCCRN-E는 마침내 실시간 트랙으로 선택되었다. 리버브 세트의 성능을 향상시키기 위해, 우리는 학습(훈련) 세트에 더 많은 RIR을 추가하여 비실시간 트랙을 위해 선택된 DCCRN-E-Aug라는 모델을 만든다. <표 3>에 설정된 최종 블라인드 테스트 결과에 따르면 DCCRN-E-Aug의 MOS는 리버스 세트에 0.02로 약간 개선되었다. <표 3>은 챌린지 주관자가 제공한 두 트랙의 여러 상위 시스템에 대한 최종 P.808 주관적 평가 결과를 요약한 것이다. 우리가 제출한 모델이 전반적으로 성능이 우수하다는 것을 알 수 있다. DCCRN-E는 모든 세트에서 평균 3.42의 MOS를 달성하고 비반전 세트에서 4.00을 달성했다. PyTorch로 구현한 DCCRN-E(ONNX에서 내보내기)의 단일 프레임 처리 시간은 Intel i5-8250U PC에서 경험적으로 테스트한 3.12ms이다. 일부 향상된 오디오 클립은 https://huyanxin.github.io/DeepComplexCRN에서 찾을 수 있다.
4. Conclusions
이 논문에서, 우리는 Speech Enhancement를 위한 DCCRN (Deep Complex Convolution Recurrent Network)를 제안했다. DCCRN 모델은 Complex valued 스펙트럼 모델링을 위해 Complex Network를 사용한다. Complex Convolution 규칙 제약 조건으로 DCCRN은 유사한 모델 파라미터 구성에서 PESQ와 MOS 측면에서 다른 것들보다 더 나은 성능을 달성할 수 있었다. 향후, 우리는 에지 장치와 같은 낮은 계산 시나리오에서 DCCRN을 구축하려고 노력할 것이다. 우리는 또한 반향 조건에서의 향상된 잡음 억제 능력으로 DCCRN을 활성화할 것이다.
[딥러닝 공부할 때 알아야 기본]
- 푸리에 변환 개념 잡자. 푸리에 변환에 반드시 필요한 개념 4가지를 순차적으로 설명 해 보자
'AI-Study' 카테고리의 다른 글
| AI Model 학습을 위해 소유하고 싶은 서버(HW) 스펙 (1) | 2021.08.03 |
|---|---|
| Deep Learning Paper Review: Malware Detection (2) | 2021.06.27 |
| Deep Learning Paper Review: (UNetGAN) Speech Enhancement (4) | 2021.06.24 |
| Deep Learning Paper Review: (FULLSUBNET) Speech Enhancement (2) | 2021.06.22 |
| Deep Learning Paper Review: (SEGAN) Speech Enhancement (4) | 2021.06.21 |