Ensemble Learning Method
| 앙상블 학습(Ensemble Learning) |
| 앙상블은 조화로움을 뜻함, 앙상블 학습을 통한 분류는 여러 개의 모델을 학습시켜서 각각의 분류기(Classifier)을 생성하고, 각각의 예측 결과를 한번에 결합함으로써 보다 더 정확한 최종 예측을 도출하는 기법을 말함. 앙상블 모델은 정형 데이터의 분류 분야 혹은 회귀 분야에서 예측 성능이 매우 뛰어난 학습 모델을 만드는데 용이함 . |
| 앙상블 종류 |
| 1. Voting 2. Bagging - Random Forest 3. Boosting - AdaBoost, Gradient Boost, XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost) 4. Stacking |
| 1. Voting [참조] |
| Voting에는 Hard Voting과 Soft Voting이 있음. Hard voting : 다수의 Classifier의 예측 결과값을 다수결로 최종 class를 결정함. Soft voting : 다수의 Classifier의 예측 결과값간 확률을 평균하여 최종 class를 결정함. 일반적으로 Soft voting이 성능이 우수하여 주로 사용됨. ★ Classifier Model : 여러가지 서로 다른 모델을 사용함. ★ Data Set : 서로 같은 Data Set을 사용해서 학습함. |
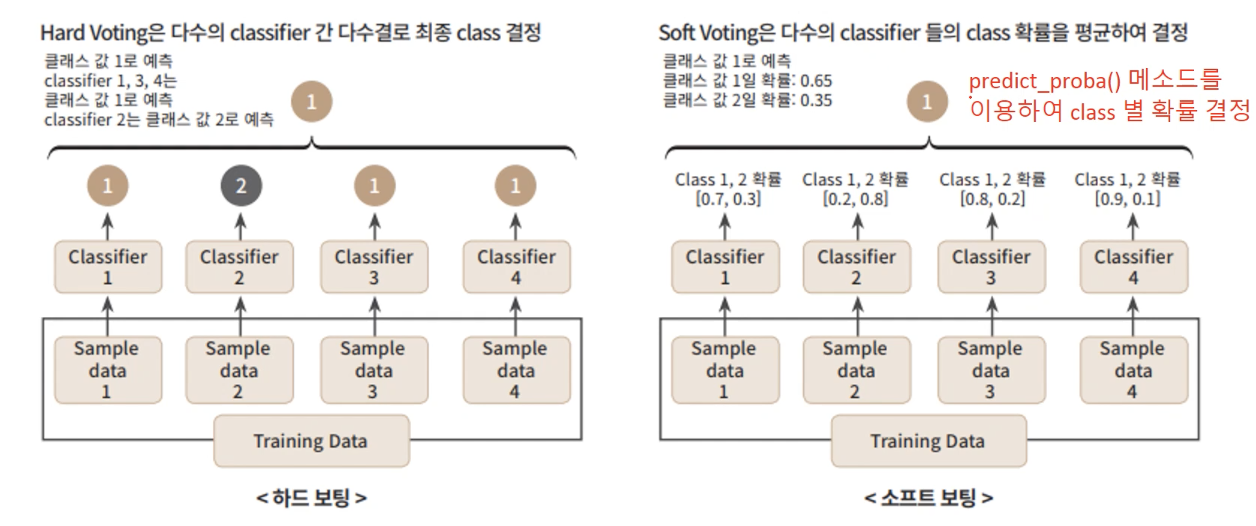
| 2. Bagging [참조] |
| Bagging은 Bootstrap Aggregation의 약자(Bootstrapping: 중복 허용 데이터 샘플링). Bagging의 핵심은 데이터의 샘플링, 전체 학습 데이터에서 개별 데이터 세트들로 샘플링 하고, 대부분 결정 트리 알고리즘을 사용함. 샘플링 된 개별 데이터 서브세트를 가지고 같은 (결정 트리) classifier이 학습을 하고, 각각의 class에 대한 확률을 평균을 내서 최종 예측값을 도출함. Bagging의 대표적인 결정 트리 알고리즘은 랜덤 포레스트(Random Forest). 랜덤 포레스트 알고리즘은 앙상블 알고리즘들 중 비교적 빠른 수행 속도를 보이며, 다양한 영역에서 높은 예측(추론) 성능을 보임. 학습 및 추론 방법 : Bootstrapping된 학습데이터로 K개의 모델을 학습 시킨 뒤, 학습된 K개의 모델을 붙여서 배깅 모델을 만듭니다. 테스트 데이터가 들어오면, K개의 모델에서 결과를 도출한 뒤, 평균 값 또는 다수 값으로 결과를 추론(예측)함. ★ Classifier Model : 동일한 모델을 사용함. ★ Data Set : 서로 다른 Data Set을 사용해서 학습함(중복 허용 데이터 샘플링). |
※ Voting 과 Bagging Ensemble Method의 차이를 명확히 알자
| 3. Boosting |
| AdaBoost [참조] Gradient Boost [참조] XGBoost(eXtra Gradient Boost) [참조] LightGBM(Light Gradient Boost) |
| 4. Stacking |
| 서로 다른 종류의 모델을 여러개 붙인 뒤 사용. 예를 들어 결정트리 1개, SVM 1개, KNN 1개 .. 이런식으로 다양한 모델을 하나의 모델로 붙여 사용함. 여러가지 예측 값을 다시 학습 데이터로 만들어서 다른 모델로 재학습 시키고, 결과를 추론(예측) 함. 개별적인 Base Learner들은 성늘이 비슷한 여러 개의 모델을 가리킴. Meta Learner는 Base Learner들이 만든 예측 데이터를 학습데이터로 사용할 최종 모델임. [장점] : 단일 모델에 비해 성능이 확실히 향상됨. 또한 앙상블의 본래 목적인 High Variance Problem을 해결하는데 크게 기여할 가능성이 높음 [단점] : Overfitting 발생 가능성이 높음. 성능향샹을 위해서 많은 개별 모델이 필요함(2~3개의 모델로는 성능 향상이 어려움) |

[ 알아두면 좋은 퀴즈 ]
앙상블은 ( 1 )을 뜻하고, 앙상블 방식의 학습을 통한 분류는 여러 개의 모델을 학습시켜서 각각의 분류기(Classifier)을 생성하고, 각각의 예측 결과를 한번에 ( 2 )함으로써 보다 더 정확한 최종 예측을 도출하는 기법을 말한다. 앙상블 방식은 정형 데이터의 ( 3 )분야 혹은 ( 4 )분야에서 예측 성능이 매우 뛰어난 학습 모델을 만드는데 용이하다. 이러한 앙상블 방식은 4가지가 있으며, 첫번째 방식은 여러가지 서로 다른 ( 5 )모델을 사용하고 같은 Data Set을 학습해서 사용하는 ( 6 ) 방식이 있으며, 두번째 방식은 동일한 ( 5 )모델을 사용하고 서로 다른 Data Set을 사용하는 ( 7 ) 방식이 있다. 세번째 방식은 여러 개의 ( 8 )를 순차적으로 학습, 예측하면서 잘못 예측한 데이터에 ( 9 )를 부여하여 오류를 개선해 나가면서 학습하는 ( 10 ) 방식이다. 다만 이 방식은 다만 '순차적으로' 학습하기 때문에 수행시간이 상대적으로 길다는 단점이 있다. 마지막 네번째 방식은 서로 다른 종류의 모델을 여러개 붙인 뒤 사용한다. 예를 들어 결정트리 1개, SVM 1개, KNN 1개 .. 이런식으로 다양한 모델을 하나의 모델로 붙여 사용하고 여러가지 예측 값을 다시 학습 데이터로 만들어서 다른 모델로 재학습 시키고, 추론(예측) 한다. 이 과정에서 개별적으로 사용하는 모델들을 ( 11 )라고 하고 이것은 성능이 비슷한 여러 개의 모델을 사용한다. 이와같이 네번째 방식은 개별적인 ( 11 )들이 만든 예측 데이터를 학습데이터로 사용하는 ( 12 )로 최종 추론결과를 만들어 내는데 이 방식이 ( 13 )방식 이다.
[ 퀴즈 ]
(1) Ensemble AI Model 4가지 & 특징
(2) Confusion Matrix : Measure(Metric)의 기본
| 예측 [ ] | 예측 [ ] | |
| 실제 [ ] | ? | ? |
| 실제 [ ] | ? | ? |